In the rapidly evolving landscape of artificial intelligence, creating smart agents that can access and reason with specific knowledge is a game-changer. While concepts like “vector databases” and “embeddings” might sound complex, building your own intelligent agent using Retrieval-Augmented Generation (RAG) is more accessible than ever—no coding required.
This guide will walk you through building a functional, no-code RAG agent using the powerful workflow automation tool n8n, along with OpenAI, Supabase for vector storage, and Postgres for memory. We will deconstruct the process, from ingesting a custom document to chatting with an AI that uses it for context.
What is a RAG Agent?
At its core, Retrieval-Augmented Generation (RAG) is a technique that enhances an AI’s ability to answer questions by first retrieving relevant information from an external knowledge source. Think of it as giving your AI a library to consult before it speaks. Instead of relying solely on its pre-trained, general knowledge, which can be outdated or lack specific context, the RAG agent can pull in precise, up-to-date, or private data.
In this tutorial, we will build an agent that can answer questions about the rules of golf by consulting a PDF document we provide. When a user asks a question, the agent will:
- Retrieve: Search our document for the most relevant sections.
- Augment: Add this retrieved information as context to the user’s query.
- Generate: Formulate a precise answer based on the provided context.
The Architecture: A Tale of Two Workflows
Our no-code RAG system in n8n is composed of two main parts:
- The RAG Pipeline: This is the data ingestion workflow. Its job is to take our source document (a PDF of golf rules), break it down, convert it into numerical representations (embeddings), and store them in a specialized vector database.
- The RAG Agent: This is the interactive workflow. It receives user questions, uses a tool to search the vector database for relevant information, and leverages a large language model (LLM) to generate an intelligent, context-aware response. It also maintains a memory of the conversation.
Download workflow: https://romhub.io/n8n/RAG_Agent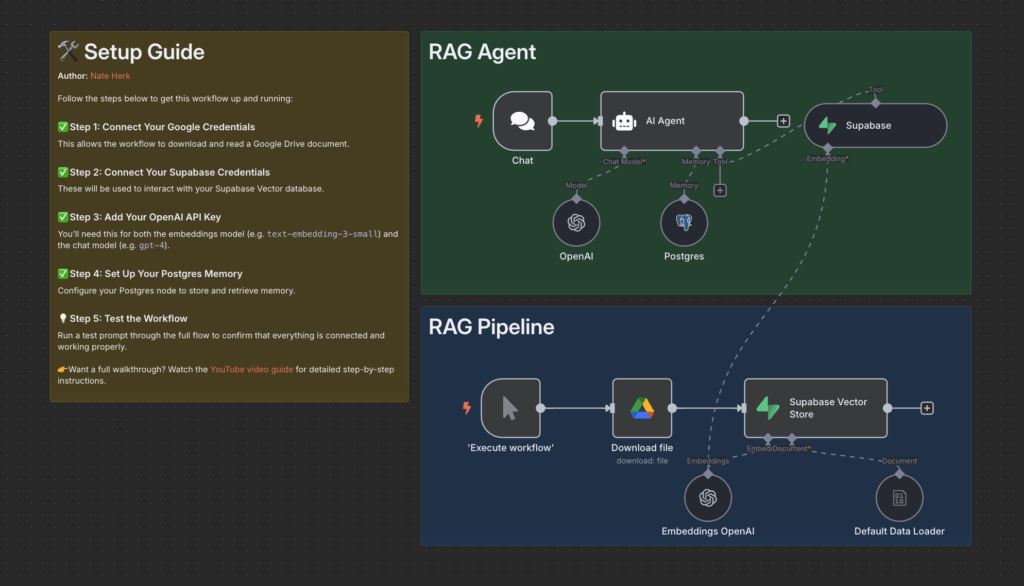
Part 1: Building the RAG Pipeline to Ingest Your Data
Before our agent can answer questions, we must provide it with knowledge. This process involves taking our document and preparing it for the AI to search.
Key Components of the Pipeline:
- Manual Trigger: To start the process.
- Google Drive Node: To download our source file (“Rules_of_Golf_Simplified.pdf”).
- Default Data Loader: To load the binary PDF data and split it into manageable text chunks.
- OpenAI Embeddings Node: To convert each text chunk into a numerical vector using a model like
text-embedding-3-small. - Supabase Vector Store Node: To store these vectors in a dedicated database table.
Step-by-Step Setup Guide:
- Prepare Your Tools:
- n8n: Set up a cloud or local instance.
- Supabase: Create a new project. You’ll get a Postgres database with the
pgvectorextension, which is perfect for our needs. In the SQL Editor, create a table to store your vectors (e.g., nameddocuments). - OpenAI: Get an API key from your OpenAI account.
- Build the Ingestion Workflow in n8n
- Trigger: Start with a
'Execute workflow'(Manual Trigger) node. - Download File: Add a
Download file(Google Drive) node. Authenticate your account and select the PDF file you want the agent to learn from. - Load and Chunk Data: Connect a
Default Data Loadernode. This node will automatically handle the “chunking” process, which breaks the large document into smaller pieces suitable for embedding. - Create Embeddings: Add an
Embeddings OpenAInode. Connect your OpenAI credentials and select an embedding model. This node takes the text chunks and turns them into vectors. - Store in Supabase: Finally, add a
Supabase Vector Storenode.- Set the operation to
Insert. - Connect your Supabase credentials.
- Select the
documentstable you created earlier. - Connect the
Embeddings OpenAInode to the embedding input.
- Set the operation to
- Trigger: Start with a
Run this workflow once. It will download the PDF, chunk it, create embeddings for each chunk, and load them into your Supabase database. Your knowledge base is now ready.
Part 2: Building the Interactive RAG Agent
With our data indexed in Supabase, we can now build the AI agent that will interact with users.
Key Components of the Agent:
- Chat Trigger: To allow real-time interaction with the agent.
- AI Agent Node: The central hub that orchestrates the agent’s behavior.
- OpenAI Chat Model: The “brain” of the agent (e.g.,
gpt-4.1-mini). - Supabase Vector Store (as a Tool): The “retriever” that searches the knowledge base.
- Postgres Chat Memory: To remember the conversation history.
Step-by-Step Agent Setup:
- Initiate the Agent Workflow:
- Start with a
Chat(Chat Trigger) node. This creates a chat interface for you to talk to the agent. - Connect it to an
AI Agentnode.
- Start with a
- Configure the AI Agent Node: The
AI Agentnode is where you plug in the different components.- Language Model: Connect an
OpenAI(lmChatOpenAi) node. Select a powerful model likegpt-4.1-miniand provide your credentials. - Memory: Connect a
Postgres(memoryPostgresChat) node. Configure it with your Supabase database credentials. This gives the agent conversational memory, allowing for follow-up questions. - Tool (The Retriever): This is the most critical part of the RAG setup.
- Add a
Supabase(vectorStoreSupabase) node and configure it as a tool. - Set the Mode to
retrieve-as-tool. - In the Tool Description, write a clear instruction for the agent, such as: “Call this tool to look up the rules of golf.” This tells the AI when to use its knowledge base.
- Select the same
documentstable used in the ingestion pipeline. - Crucially, connect the same
Embeddings OpenAInode from your pipeline to this tool. This ensures the user’s question is converted to a vector in the same way the source document was.
- Add a
- Language Model: Connect an
Testing Your No-Code RAG Agent
Activate your workflow and open the chat panel in n8n. Start asking questions about your document. For example:
- “What are my options if my ball lands in a bunker?”
- “Can I repair pitch marks on the green?”
When you send a message, you can observe the AI Agent node’s execution log. You will see it:
- Receive your query.
- Decide to use the Supabase tool based on your prompt and the tool’s description.
- Retrieve the most relevant text chunks from the golf rules PDF.
- Feed your original query and the retrieved context into the
gpt-4.1-minimodel. - Generate a final, accurate answer based on the provided information.
Thanks to the Postgres memory node, you can also ask follow-up questions like, “What about in a penalty area?” and the agent will understand the context of the conversation.
Conclusion
You have successfully built a complete, end-to-end RAG agent without writing a single line of code. By combining the workflow automation of n8n, the powerful language models of OpenAI, and the accessible vector database capabilities of Supabase, you can create highly intelligent and context-aware AI systems.
This foundation is incredibly powerful. You can expand it by ingesting multiple documents, connecting to other data sources like Notion or a CRM, and triggering the agent through various channels like Slack or email. The era of building bespoke, knowledgeable AI is here, and with the right tools, it’s accessible to everyone.