Qwen-Image is an open-source text-to-image model known for accurate text rendering—especially for Chinese characters—so you can place multi-line, paragraph-level text directly inside images for posters, banners, and creative assets. Recent releases in the Qwen family also highlight precise, bilingual text editing in images, which is ideal for iterative design workflows.
Commercial plugins often charge per image once you pass a free tier (sometimes around $0.25/image), which adds up fast for batch generation and frequent edits. This guide shows a cost-savvy path using Dify, ModelScope, the Qwen-Image plugin, and Tencent Cloud Object Storage (COS) to create an agent that both generates images from text and edits them over multiple turns.
What you’ll set up
The system centers on Dify plus the Qwen Text2Image & Image2Image plugin:
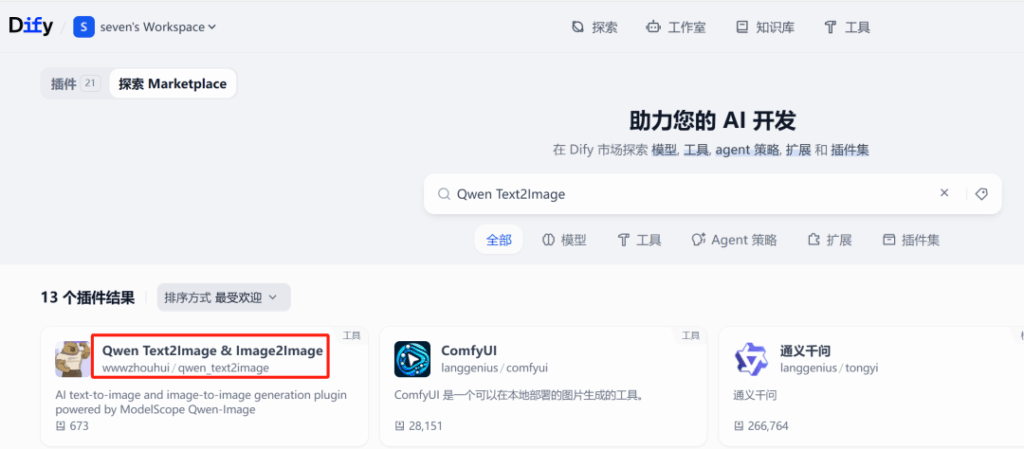
1) Dify Plugin Marketplace + Qwen-Image
Dify is an open-source platform for building agentic AI apps and drag-and-drop workflows. Install the Qwen Text2Image & Image2Image plugin from Dify’s marketplace to unlock both generation and editing via ModelScope’s Qwen models.
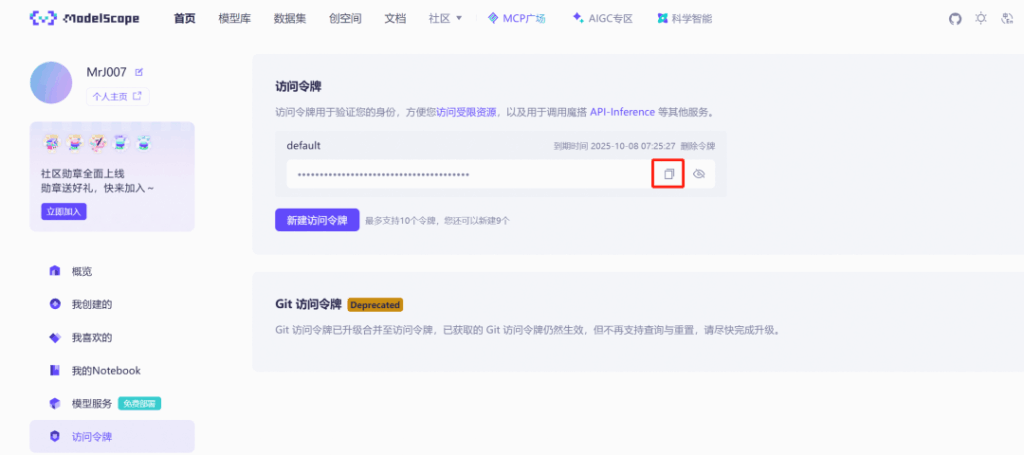
2) ModelScope access token
You’ll need a ModelScope API token to call Qwen-Image through the plugin. Create or retrieve a token in your ModelScope account’s Access Tokens page.
Get your token here: https://modelscope.cn/my/myaccesstoken
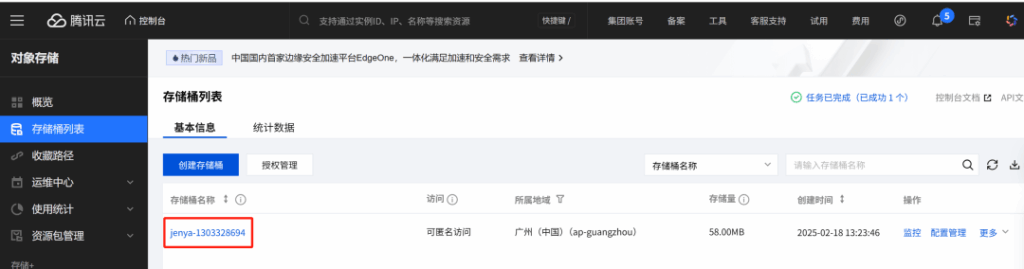
3) Tencent Cloud COS for public image links
Qwen-Image’s image-to-image editing expects the source image to be reachable via a public URL. Store outputs in Tencent Cloud COS and serve them through the standard myqcloud.com domain format (e.g., https://examplebucket-APPID.cos.ap-guangzhou.myqcloud.com/object.png). COS is S3-compatible, so common S3 SDKs and patterns work out of the box.
Console: https://console.cloud.tencent.com/cos/bucket
4) A tiny upload API
To let Dify upload images into COS during the workflow, spin up a lightweight FastAPI service that accepts a file, saves it, uploads to COS, and returns a public URL.
TIP:
Never hard-code credentials in production. Use environment variables or a secret manager.# main.py (trimmed for clarity)
import base64, os, io, datetime, random
from PIL import Image
from qcloud_cos import CosConfig, CosS3Client
from fastapi import FastAPI, UploadFile, File, HTTPException
output_path = "D:\\tmp\\zz"
region = "ap-guangzhou"
secret_id = "AKIDxxxxxxxxxxxx"
secret_key = "xxxxxxxxxxxxxx"
bucket = "jenya-130xxxx694"
app = FastAPI()
def stamp(ext='png'):
t = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
r = random.randint(1000, 9999)
return f"{t}_{r}.{ext}"
def to_file(b64, out_dir):
name = stamp()
path = os.path.join(out_dir, name)
Image.open(io.BytesIO(base64.b64decode(b64))).save(path)
return name, path
def upload_cos(name, base):
client = CosS3Client(CosConfig(Region=region, SecretId=secret_id, SecretKey=secret_key))
path = os.path.join(base, name)
res = client.upload_file(Bucket=bucket, LocalFilePath=path, Key=name)
if res and 'ETag' in res:
return f"https://{bucket}.cos.{region}.myqcloud.com/{name}"
return None
@app.post("/upload_image/")
async def upload_image(file: UploadFile = File(...)):
content = await file.read()
name, path = to_file(base64.b64encode(content).decode(), output_path)
url = upload_cos(name, output_path)
if url:
return {"filename": name, "local_path": path, "url": url}
raise HTTPException(status_code=500, detail="Upload failed.")Run:
uvicorn main:app --host 0.0.0.0 --port 8083
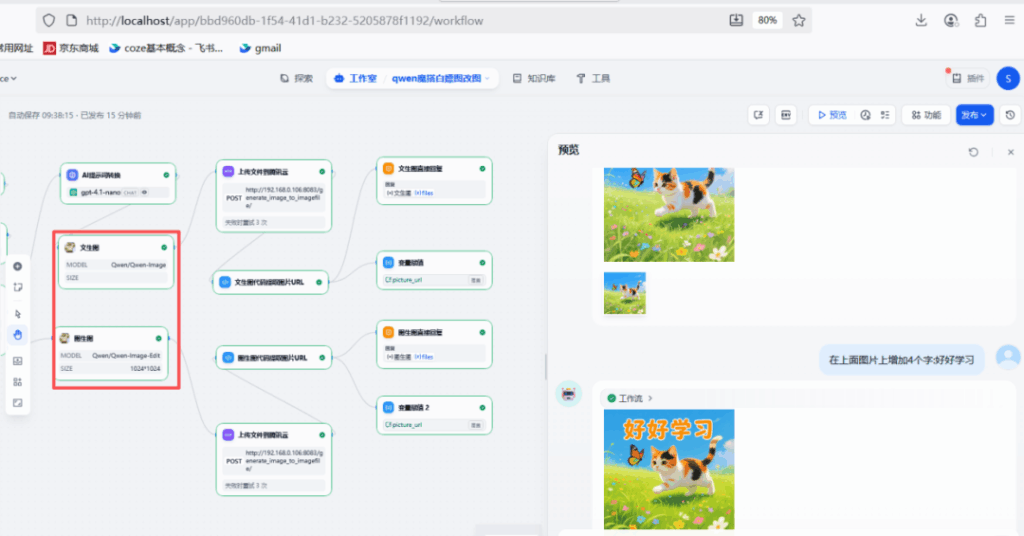
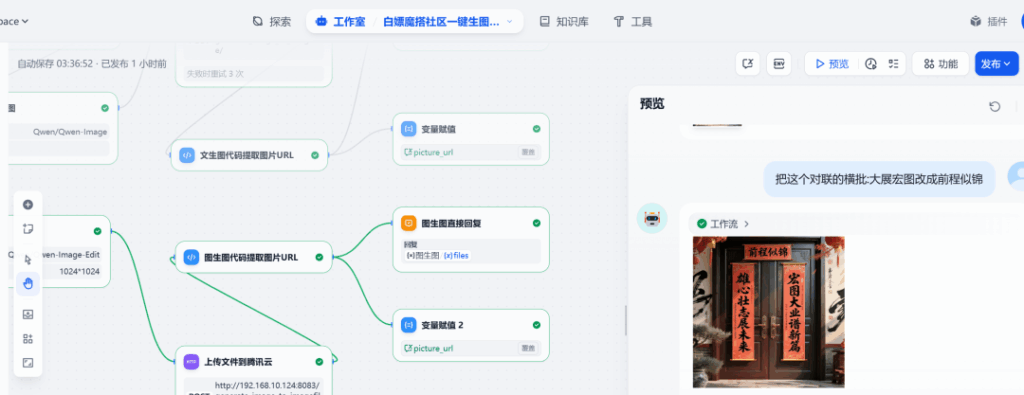
The Dify workflow (multi-turn)
Goal: build an agent that understands whether a user wants to create a new image or edit the last image, then routes accordingly.
Key pieces:
- Parameter extractor — detects intent.
- HTTP request — uploads the generated file to your
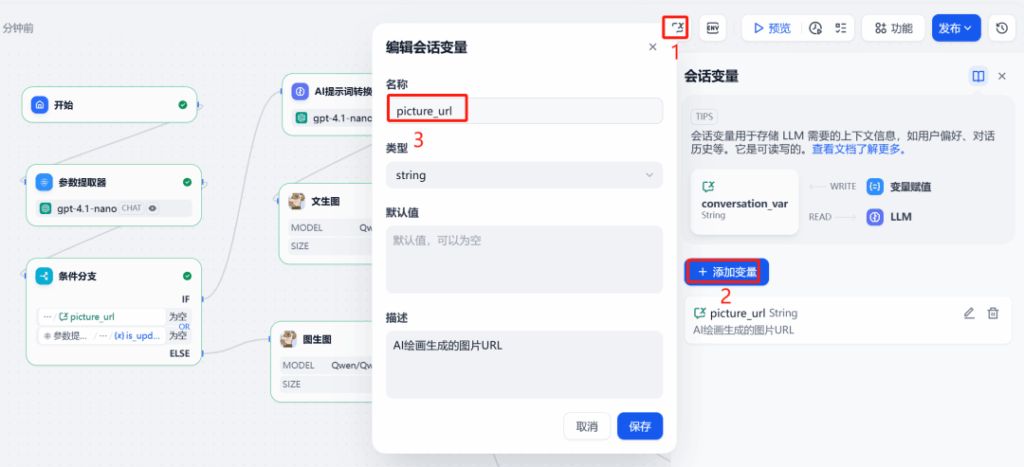
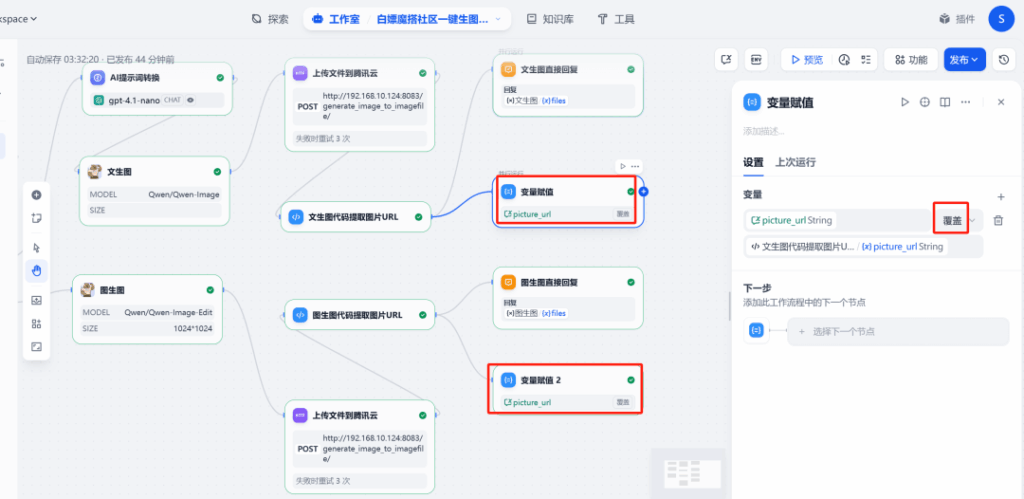
/upload_image/endpoint and gets a public URL back. - Session variable — stores
picture_urlfor the latest image so future edits always target the right file.
1) Start node
Entry point; default config works.
2) Parameter extractor
Use a reasoning-strong LLM to assign is_update = 0 (new image) or 1 (edit existing).
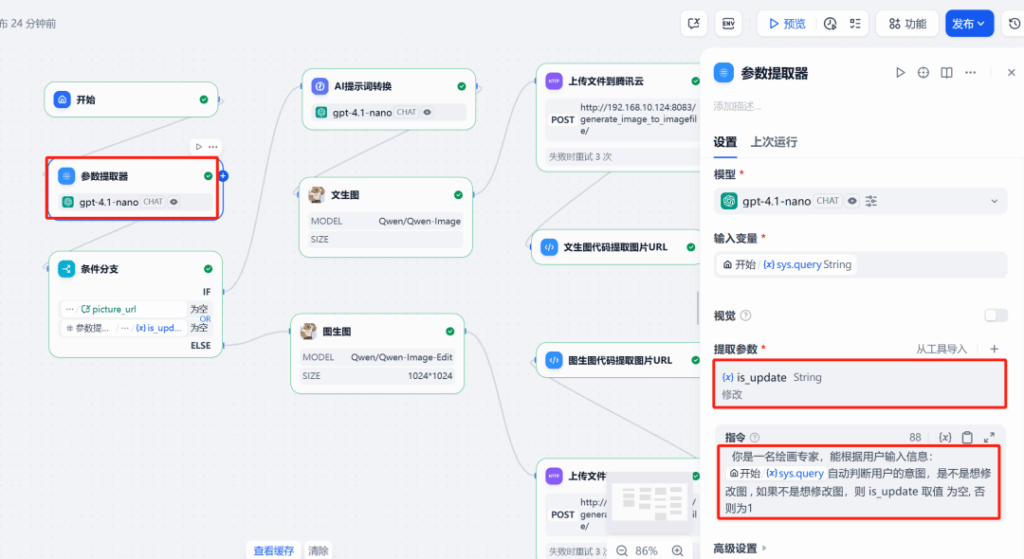
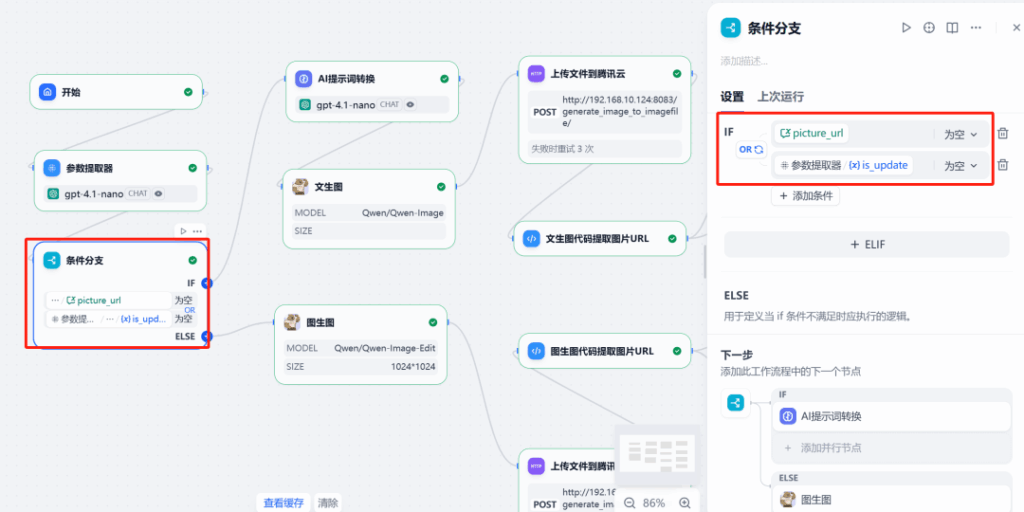
3) Session state + branching
Keep picture_url in session memory. Route to Generate when is_update = 0, or Edit when is_update = 1 and picture_url exists.
4) Prompt polishing with an LLM
Insert a prompt-optimizer node that expands the user’s brief into a safe, detailed English prompt tailored for image models. This improves Qwen-Image outputs and keeps content policy-friendly. (Qwen-Image is designed for robust text rendering and consistent edits, so better prompts pay off.)
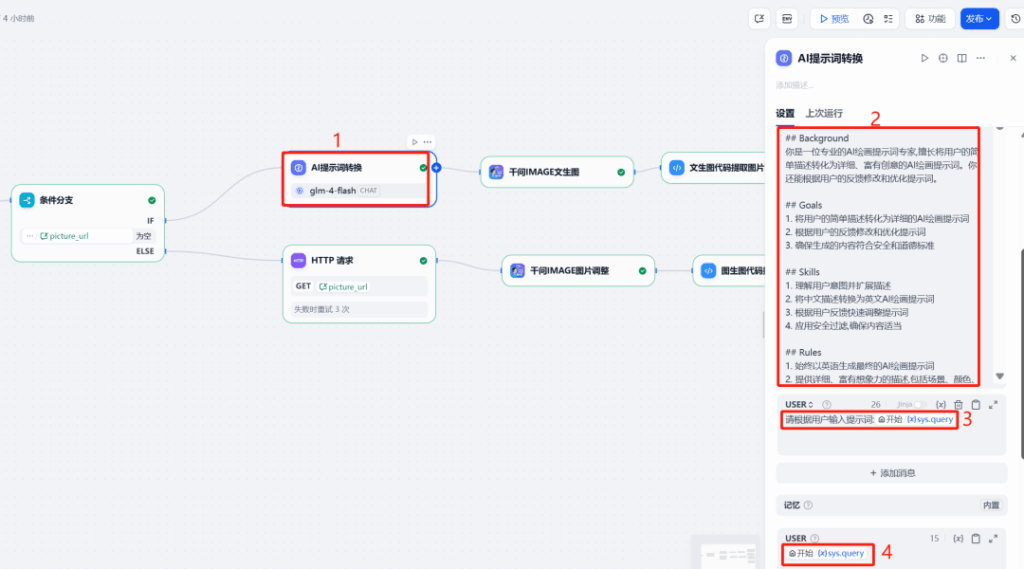
5) Call Qwen-Image
Generate branch: Feed the optimized English prompt to the Qwen Text2Image action.
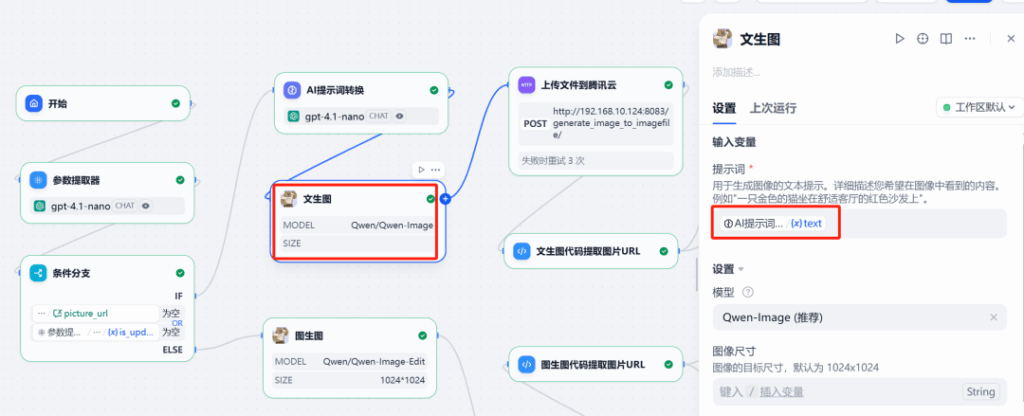
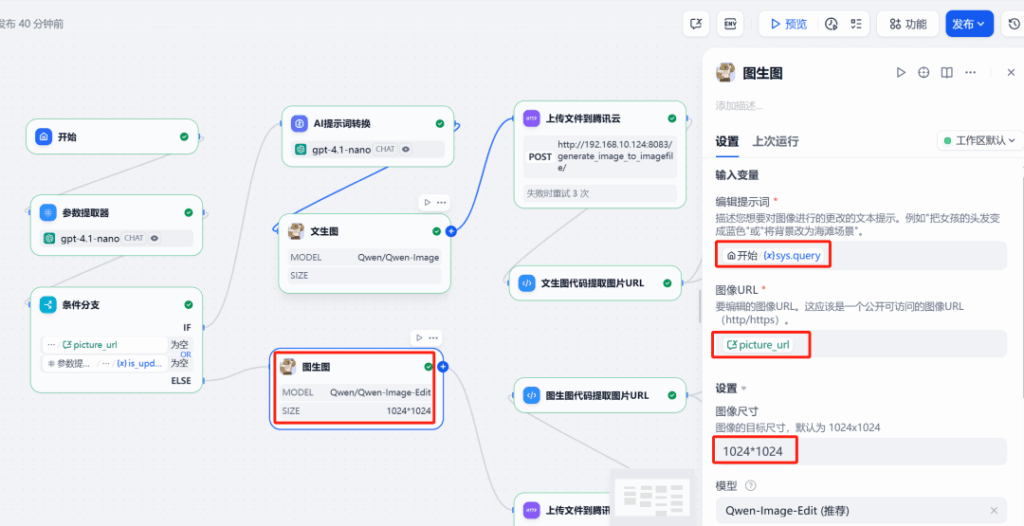
Edit branch: Pass both the source image URL (picture_url) and the updated prompt to Image2Image for text or layout changes. Qwen-Image supports high-fidelity text edits, which is perfect for revising signage, posters, and couplets.
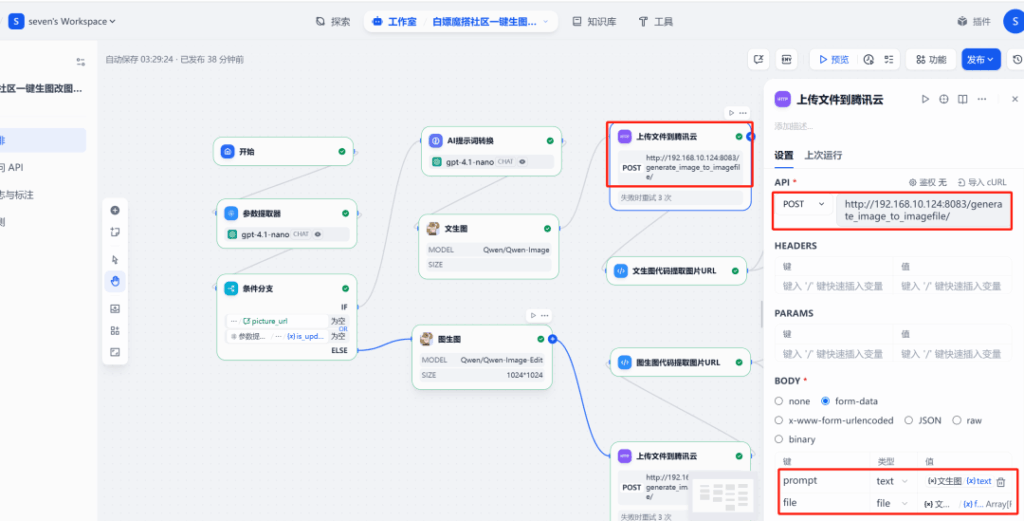
6) HTTP upload to COS
After Qwen-Image returns a file, send it to your FastAPI endpoint. The API responds with a public url hosted on myqcloud.com.
7) Extract + save the URL
Use a short code node to pull url from the JSON response and emit picture_url:
def main(arg1: dict) -> dict:
image_url = arg1.get('url')
return {"result": f"Image URL is {image_url}", "picture_url": image_url}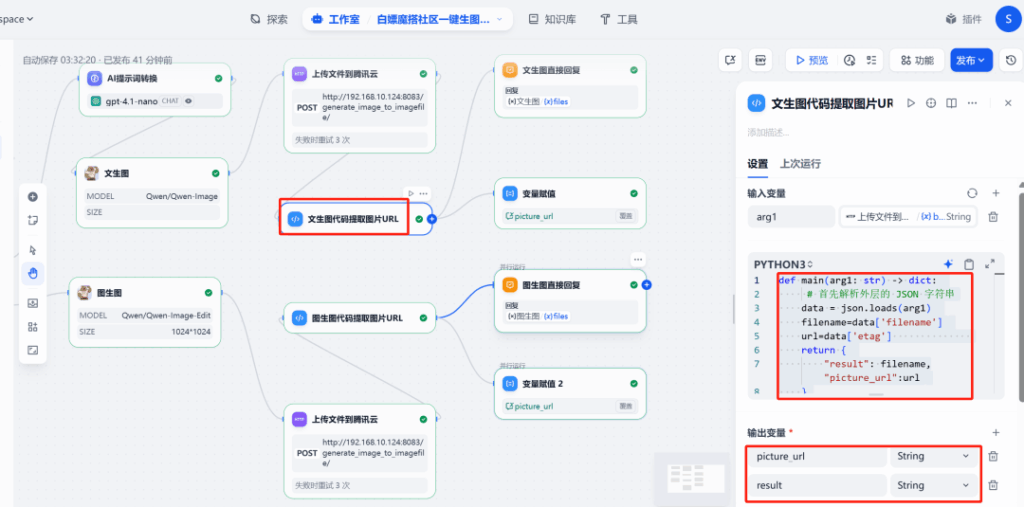
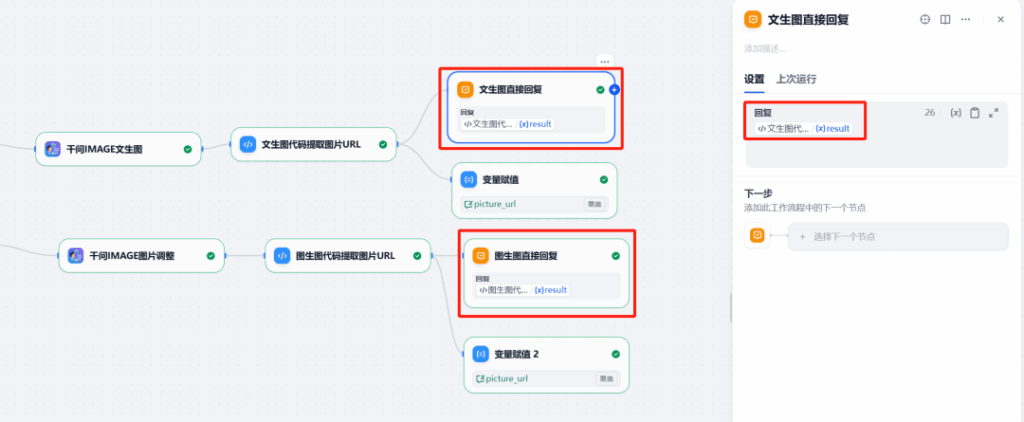
8) Show the image
Finish with a Direct response node that displays the uploaded image to the user.
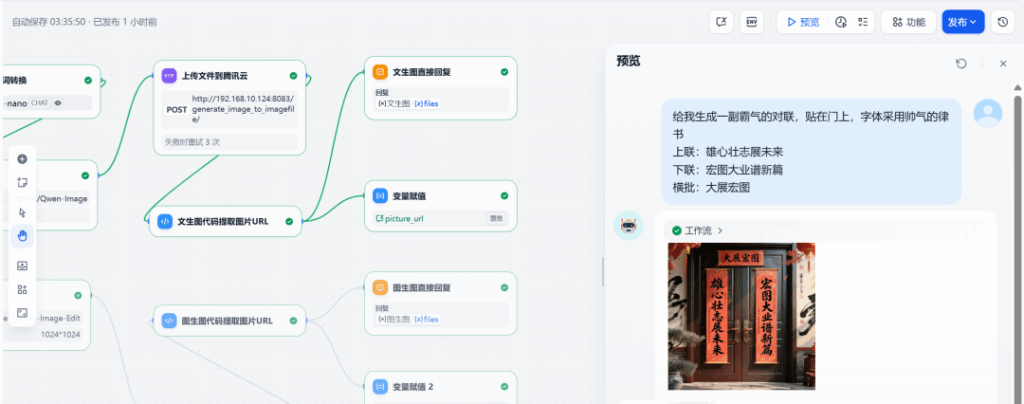
Quick tests
Test 1 — Generate
Prompt a door couplet with specific upper/lower lines and a banner. The system returns a clean, legible couplet image:
Test 2 — Edit
In the same chat, change the banner text only; the agent updates the existing image while preserving layout:
Why this stack works (and stays affordable)
- Qwen-Image for text-heavy visuals: purpose-built for complex text rendering and consistent edits.
- Dify for orchestration: open-source, agent-first workflows with a ready plugin system.
- ModelScope integration: straightforward token setup to access Qwen models.
- COS hosting: S3-compatible storage with predictable public URLs for image-to-image steps.
This setup gives you a multi-round, text-to-image and image-to-image editor that’s flexible, fast, and close to zero marginal cost—great for iterative creative work without per-image sticker shock.