In the rapidly evolving landscape of AI, the ability to interact with your own data privately and securely is becoming paramount. While cloud-based solutions offer convenience, they often come with concerns about data privacy and vendor lock-in. This is where local Retrieval Augmented Generation (RAG) systems shine, allowing you to leverage powerful language models on your local machine without sending your sensitive information anywhere.
My journey into developing and refining such systems has led me to a new iteration of localGPT, an open-source project designed specifically for this purpose. This new version isn’t just an update; it’s a more opinionated framework, offering unprecedented control and flexibility to build and fine-tune your ideal private RAG solution.
What Makes localGPT 2.0 a Game-Changer for Private RAG?
LocalGPT 2.0 reimagines how you interact with your documents by providing a robust, entirely private ecosystem for RAG. Unlike many solutions that rely on external APIs, localGPT ensures that all your data and model interactions remain securely on your local machine. This privacy-first approach is powered by local models, significantly enhancing security for sensitive documents.
The updated interface is notably cleaner and more intuitive than previous versions, simplifying the process of creating, managing, and interacting with your document indexes. This release focuses on empowering users to experiment with different hyperparameters and retrieval strategies, making it a powerful framework for developing highly effective RAG pipelines.
Initial Setup and Core Functionality
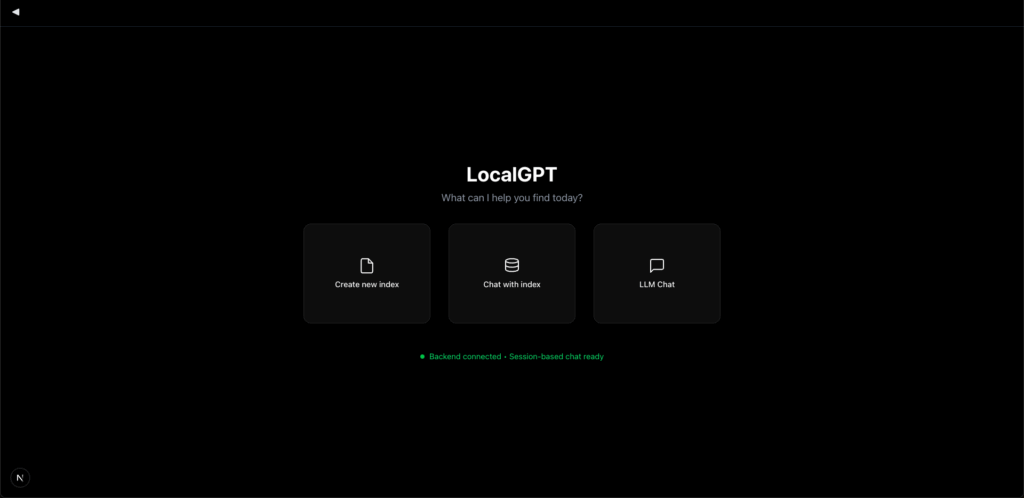
Upon launching localGPT 2.0, you’re presented with a clear set of options:
- Create a new index: Begin building a fresh knowledge base from your documents.
- Select an existing index: Load and interact with previously created indexes.
- Directly chat with a local model: Leverage the power of local LLMs for general queries, even without a specific document index. This functionality is seamlessly integrated with Ollama, allowing you to choose from any LLM available on your Ollama instance. The initial response might take a moment as the model is pulled, but subsequent interactions are significantly faster.
This streamlined entry point makes it easy to dive into the core capabilities, whether you’re starting fresh or continuing a previous session.
Deep Dive into Indexing and Retrieval Customization
One of the most compelling aspects of localGPT 2.0 is the depth of customization available for your indexing and retrieval processes. This flexibility is crucial for optimizing your RAG system to suit the unique characteristics of your data and your specific use cases.
Tailoring Your Indexing Strategy
When creating a new index, you’ll encounter several critical options that directly influence retrieval quality and indexing speed:
- Hybrid Retrieval: My strong recommendation is to use hybrid search, which combines dense embeddings with full-text search. This approach generally yields the most robust retrieval results by leveraging both semantic understanding and keyword matching.
- Late Chunking (Advanced): While not enabled by default, localGPT 2.0 supports late chunking. This is an advanced technique where the system re-chunks documents at query time based on context. I advise creating multiple indexes with and without this option and testing them against your specific questions to determine optimal performance.
- High Recall Chunking (Sentence-Level): For maximum accuracy, you can enable high recall chunking, which processes documents at the sentence level. This results in much more granular and precise chunks, significantly boosting recall. However, be aware that this process can be considerably slower due to the increased number of chunks generated. The overall indexing process in localGPT 2.0 might feel slower than some other solutions, but this is a direct result of the rich, customizable options available for higher quality indexing.
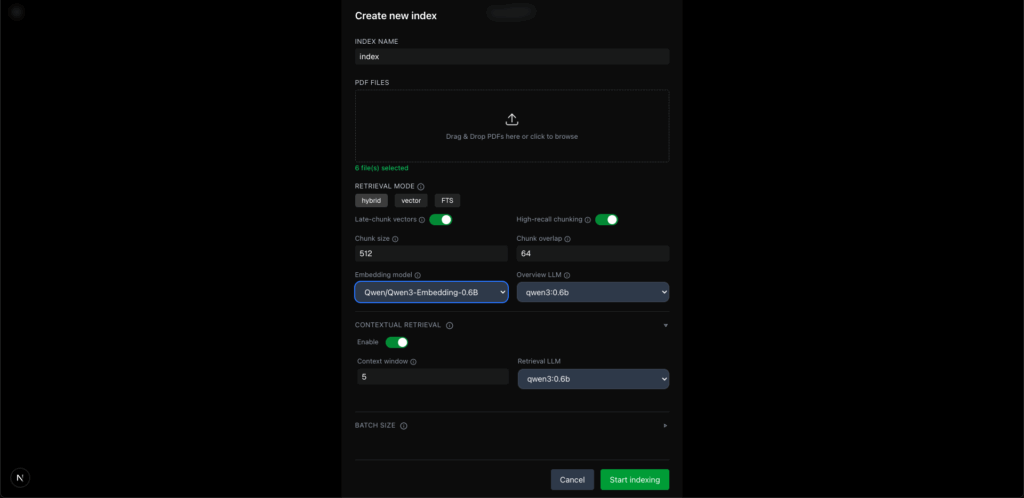
Choosing Your Embedding Models
LocalGPT 2.0 offers flexibility in selecting embedding models:
- Built-in Models: By default, several common embedding models are available. The first time you use one, it will be downloaded locally.
- Ollama Hosted Models: If you have embedding models running via Ollama, localGPT 2.0 can seamlessly integrate and utilize those as well. This allows you to leverage your preferred local models for generating document embeddings.
Enhancing Contextual Understanding
Two powerful features contribute to a more nuanced understanding of your documents:
- Document Overviews: For every document, localGPT 2.0 randomly selects a few chunks to create concise overviews. These summaries are crucial for the “triage” step in the RAG pipeline, where the system intelligently decides whether to use its own knowledge, chat history, or retrieve information from your indexed documents.
- Contextual Retrieval/Enhancement: Similar to approaches recommended by leading AI research, localGPT 2.0 enhances context by looking at a sliding window (currently five chunks) around a given chunk and creating a small summary. This ensures that each chunk is not isolated but understood within its local context, improving the coherence and accuracy of retrieved information. For these computationally intensive tasks, a smaller, efficient 6-billion parameter model is used, ensuring performance without sacrificing quality.
Once you’ve configured your options, simply hit “Start Indexing,” and localGPT 2.0 will begin processing your files, clearly displaying the backend operations. Upon completion, a new chat session linked to your freshly created index will automatically open, ready for interaction.
Optimizing Your Retrieval Pipeline for Diverse Queries
The true power of a RAG system lies in its ability to adapt to different types of queries and provide accurate, contextually relevant answers. LocalGPT 2.0 provides granular control over the retrieval pipeline, allowing you to fine-tune its behavior.
Customizing Retrieval Settings
Within the settings, you can customize various aspects of the retrieval pipeline:
- Complex Question Decomposition: For intricate queries, localGPT 2.0 can automatically decompose them into smaller sub-questions. You have the option to either use an LLM to generate answers for each sub-question individually or retrieve all relevant chunks and feed them directly to the final LLM for a comprehensive answer. This flexibility is invaluable for handling complex information needs.
- Search Type: Currently, hybrid search is the default and recommended search type, providing a balanced approach to retrieval.
- LLM Selection: While a robust 8-billion parameter model (like
quinn 3) is set as the default, you can easily switch to any LLM available on your Ollama instance. The choice of LLM significantly impacts the quality and reasoning capabilities of the generated answers. The default choice aims to be accessible for machines with 12-16GB of VRAM while still offering strong performance.
Understanding the RAG Pipeline in Action
When you interact with localGPT 2.0, the system intelligently determines the best approach to answer your query.
- General Questions: For simple, general questions (e.g., “Hi”), the system often uses the LLM’s internal knowledge directly, without triggering the RAG pipeline. This is efficient for queries that don’t require document retrieval.
- Triggering Retrieval: The system constantly evaluates whether your question has relevant information within the indexed documents. It does this by checking your query against the previously generated document overviews. If it finds a strong correlation, the RAG pipeline is initiated.
When the RAG pipeline is triggered, a series of sophisticated steps unfold:
- Decision Making: Determine if RAG is necessary.
- Sub-Query Generation (if complex): Break down the main question.
- Context Retrieval: Fetch relevant chunks from the index.
- Re-ranking: Prioritize the most relevant chunks.
- Context Expansion: Expand the context window around the top chunks.
- Answer Generation: Use the LLM to synthesize answers, potentially for sub-queries first, then a final answer.
This multi-stage process ensures that even complex questions are handled systematically, leading to precise and well-supported answers, often with a confidence score to gauge reliability. You can disable the confidence score calculation in settings if the extra processing time is not desired.
Refining Retrieval with Pruning and Triage
Two advanced options further enhance the precision and control of your RAG outputs:
- Pruning: When chunks are retrieved, not all sentences within them may be directly relevant to your query. The pruning feature performs sentence-level analysis, retaining only the most pertinent sentences. This dramatically reduces noise and ensures the LLM receives highly focused context, leading to more concise and accurate answers.
- RAG Node Triage: By toggling “RAG node triage,” you can explicitly force the system to always use the retrieval pipeline, completely ignoring the LLM’s internal knowledge. This is particularly useful when you want answers strictly grounded in your documents, preventing any external hallucinations from the LLM.
Tips for Effective Querying
Based on my experience, a few tips can significantly improve your results:
- Be Specific: Using precise keywords helps the system identify and retrieve the most relevant chunks.
- Guide the System: Forcing the RAG pipeline can be achieved by adding phrases like “According to this document…” at the beginning of your query. This explicitly signals to the system that it should prioritize document retrieval over the LLM’s general knowledge.
- Cache Awareness: LocalGPT 2.0 uses a cache for question-answer pairs to speed up subsequent identical queries. If you’re not getting the desired answer, try slightly rephrasing your question to bypass the cache and force a fresh retrieval.
Setting Up localGPT 2.0 on Your Machine
Getting localGPT 2.0 up and running on your local machine is straightforward, though some basic command-line familiarity is helpful. While I primarily developed and tested this on macOS, it’s designed to be cross-platform, with ongoing efforts to iron out any platform-specific bugs.
Installation Options
LocalGPT 2.0 offers flexible deployment methods:
- Docker Deployment: The easiest and most recommended method for quick setup and portability.
- Direct Deployment: For users who prefer a more hands-on approach and want direct control over dependencies.
- Manual Component Setup: Provides the most granular control, allowing you to run each component (backend, RAG system, frontend) separately. This is ideal for development and debugging.
For the purpose of getting started quickly, I’ll walk through the direct deployment. Note that localGPT 2.0 is an API-first framework, meaning you can even build your own custom UI on top of its robust backend APIs if the default interface isn’t what you need.
Step-by-Step Direct Installation
- Clone the Repository:
Navigate to the localGPT GitHub repository. This new version currently resides in a dedicated branch. Use the following command to clone it:
git clone -b localgpt-v2 https://github.com/PromtEngineer/localGPT.git localGPT- Navigate to the Directory:
cd localGPT- Install Node.js/npm:
Ensure you have Node.js and npm installed on your system, as they are required for the frontend. - Create a Conda Environment:
It’s always a good practice to use a virtual environment to manage dependencies.
conda create -n localgpt_env python=3.10 conda activate localgpt_env- Install Python Requirements:
LocalGPT 2.0 is built with minimal Python dependencies, avoiding heavy frameworks like LangChain or LlamaIndex (the entire RAG setup is implemented in pure Python). This significantly reduces dependency conflicts.
pip install -r requirements.txt- Run Ollama:
Before starting localGPT, ensure your Ollama instance is running, as it provides the local LLMs. - Start localGPT Services: You have two main ways to run the system:
- Single Command (for quick start):
python system.pyThis command will automatically start both the backend and frontend servers. You can then access the UI in your web browser athttp://localhost:3000. - Separate Components (recommended for development):
This method gives you more control and is excellent for debugging. Open three separate terminal tabs and run each command:- Tab 1 (Backend API):
python backend_server.py - Tab 2 (RAG Pipeline Server):
python rag_system_api_server.py - Tab 3 (Frontend):
npm run dev
- Tab 1 (Backend API):
- Single Command (for quick start):
Once all three services are running, access the UI at http://localhost:3000. This method is generally more robust for initial setup, as it avoids potential port conflicts that can sometimes occur with the single-command approach.
Important Considerations and Future Outlook
While localGPT 2.0 is robust, there are a couple of points to keep in mind as you use it:
- PDF Quality: The quality of the initial PDF parsing is crucial. If
doclingstruggles to correctly parse your PDF files, it can impact the entire pipeline’s performance. I am actively exploring the integration of vision-based retrieval to address this, though it would require more substantial GPU resources. - Ongoing Development: Remember, this version is a preview. You might encounter minor bugs (e.g., occasional formatting issues in streamed responses) that are actively being addressed. Your feedback is incredibly valuable in identifying and resolving these. This version will remain on a separate branch for a few weeks, and once stabilized, it will become the main branch for localGPT.
I’m truly excited about the direction localGPT is heading and the possibilities it opens up for private, powerful RAG systems.
Conclusion
LocalGPT 2.0 marks a significant leap forward in building private, customizable Retrieval Augmented Generation systems. By keeping all data and model interactions local, it addresses critical privacy concerns while delivering a highly flexible and performant framework. The ability to fine-tune indexing, choose embedding and language models, and meticulously control the retrieval pipeline empowers users to create RAG solutions perfectly tailored to their needs.
I encourage you to install localGPT 2.0 on your machine, experiment with its features, and explore how it can transform your document interactions. Your feedback is crucial as we continue to refine this project, pushing the boundaries of what’s possible with local AI. This is more than just a tool; it’s a foundation for a new era of private and intelligent data interaction.