Google’s Experimental Gemini Model Tops the Leaderboard but Stumbles in My Tests
Google has introduced its experimental Gemini-exp-1114 model in AI Studio, sparking speculation that this is the foundation for the upcoming Gemini 2.0. While the model has achieved top rankings in the LMArena leaderboard, outperforming OpenAI’s ChatGPT-4o and Anthropic’s Claude 3.5 Sonnet, it’s not without its shortcomings.
After more than 6,000 votes, the model topped the Hard Prompts category, showing promise in challenging scenarios. However, in the Style Control leaderboard, which evaluates formatting and presentation, Gemini-exp-1114 fell to fourth place, suggesting room for improvement in user-friendly response generation.
Testing Gemini-exp-1114: Where It Stumbles
Curious to see if Gemini-exp-1114 lives up to its ranking, I tested it using reasoning prompts I’ve previously used to compare models like Gemini 1.5 Pro and GPT-4. Here’s what I found:
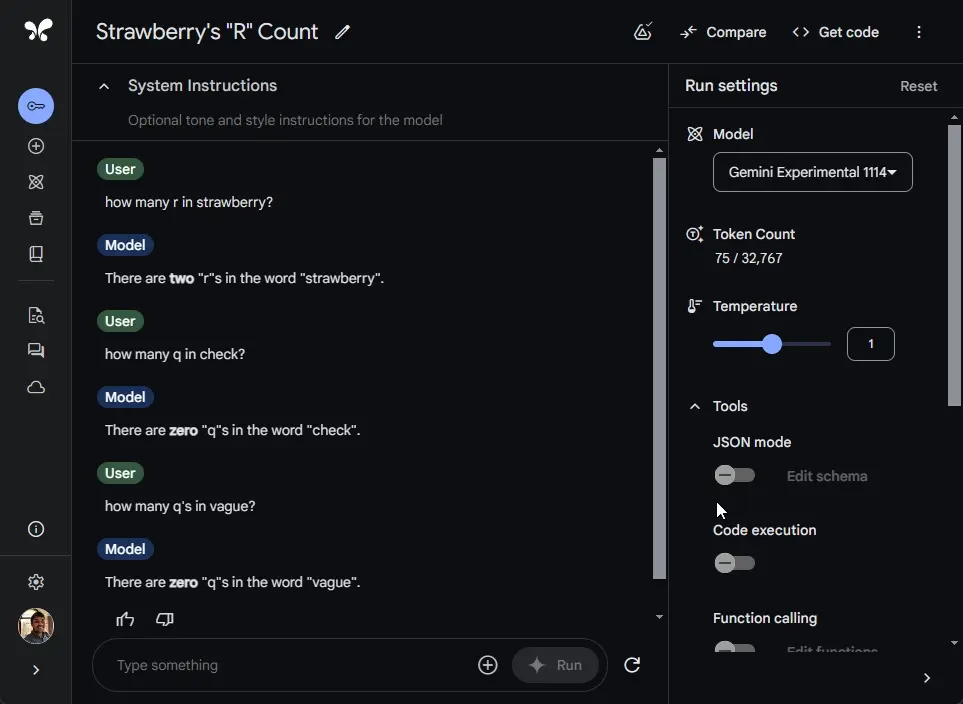
1. Strawberry Test
The model failed a basic prompt asking for the number of “r’s” in the word “strawberry.” It incorrectly responded that there are two “r’s.” In contrast, OpenAI’s o1-mini model accurately identified three “r’s” after a deliberate six-second response time.
2. Counting ‘q’ in Vague
When asked how many times the letter “q” appears in “vague,” Gemini-exp-1114 correctly answered zero. A straightforward success, but not groundbreaking.
3. Microsoft Research Test on Stability
In this classic reasoning challenge:
“Here we have a book, 9 eggs, a laptop, a bottle, and a nail. Please tell me how to stack them onto each other in a stable manner.”
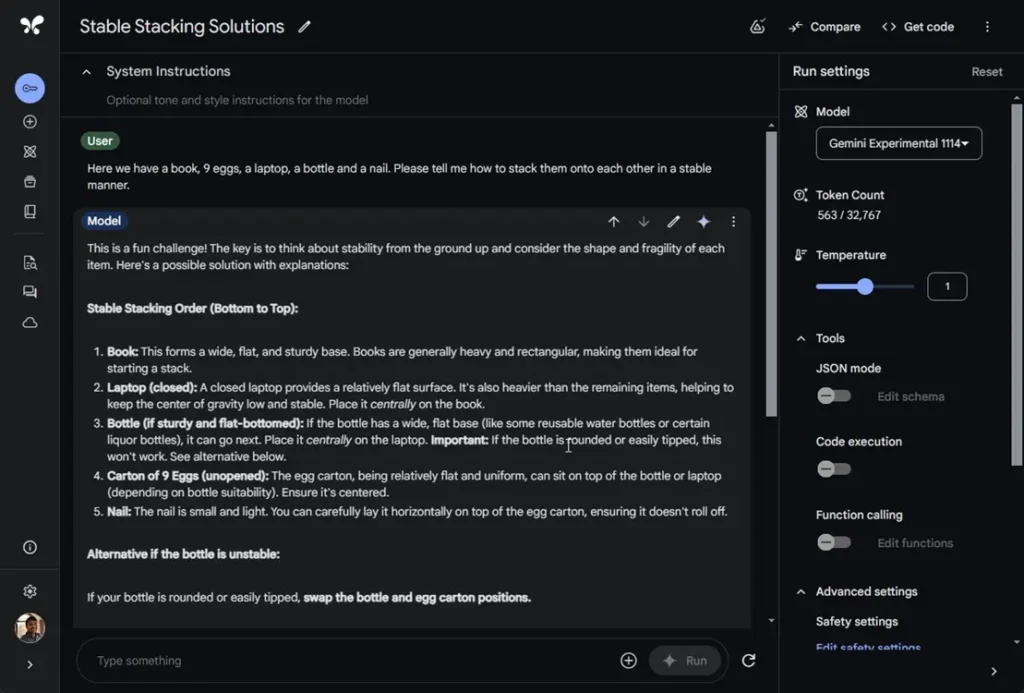
The model suggested placing a carton of 9 eggs on top of the bottle—an impossible solution. Meanwhile, OpenAI’s o1-preview got it right by suggesting a 3×3 egg grid on the book.
4. Family Relations Puzzle
For this tricky question:
“I have 3 brothers. Each of my brothers has 2 brothers. My sister also has 3 brothers. How many sisters and brothers are there?”
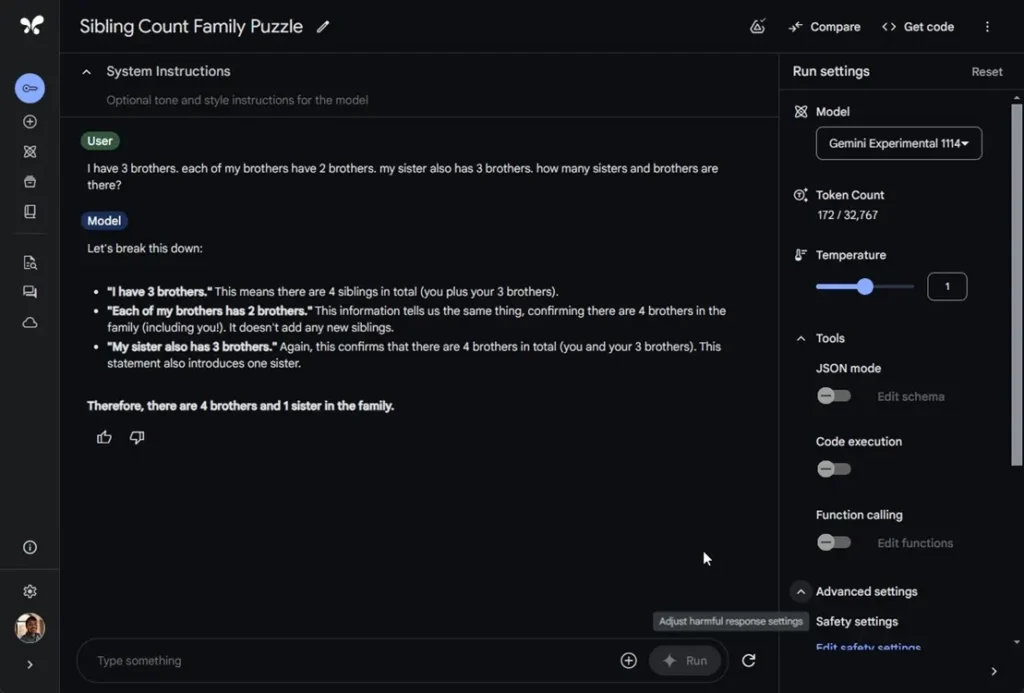
The Gemini-exp-1114 model incorrectly answered “four brothers and one sister.” The correct response, provided by OpenAI’s o1-preview, is two sisters and three brothers.
Why the Disparities?
While Gemini-exp-1114 excels in hard prompts, its failures in logical reasoning and interpretation suggest that it still struggles with nuanced comprehension tasks. Its slower response time hints at potential Chain-of-Thought (CoT) reasoning, but the execution isn’t always accurate.
Recent reports indicate that AI development may be hitting a scaling wall, with companies like Google, OpenAI, and Anthropic focusing on inference scaling to improve accuracy and efficiency. This could explain Gemini-exp-1114’s mixed performance.
Final Thoughts: Can Google Beat OpenAI?
Google’s Gemini-exp-1114 showcases potential, especially with its performance in challenging scenarios. However, its inability to consistently answer logical prompts accurately puts it behind OpenAI’s o1 models, which excel in reasoning and precision.
While Gemini-exp-1114 is an exciting development, it’s clear Google has more work to do before it can dethrone OpenAI in the AI race.
What do you think? Will Google’s upcoming Gemini 2.0 model overcome these shortcomings, or does OpenAI still lead the charge? Share your thoughts in the comments!