How to Install and Run LLMs Locally on Android Phones
- With the MLC Chat app, you can download and run AI models on your Android device locally.
- It offers several AI models like Gemma 2B, Phi-2 2B, Mistral 7B, and even the latest Llama 3 8B model.
- You may get a good performance on the latest Snapdragon phones, but on older devices, token generation is close to 3 tokens per second.
While there are apps like LM Studio and GPT4All to run AI models locally on computers, we don’t have many such options on Android phones. That said, MLC LLM has developed an Android app called MLC Chat that lets you download and run LLM models locally on Android devices. You can download small AI models (2B to 8B) like Llama 3, Gemma, Phi-2, Mistral, and more. On that note, let’s begin.
NOTE:
Currently, MLC Chat doesn’t use the on-device NPU on all Snapdragon devices so token generation is largely slow. The inference is done on the CPU alone. Some devices like Samsung Galaxy S23 Ultra (powered by Snapdragon 8 Gen 2) are optimized to run the MLC Chat app so you may have a better experience.
- Go ahead and download the MLC Chat app (Free) for Android phones. You will have to download the APK file (148MB) and install it.
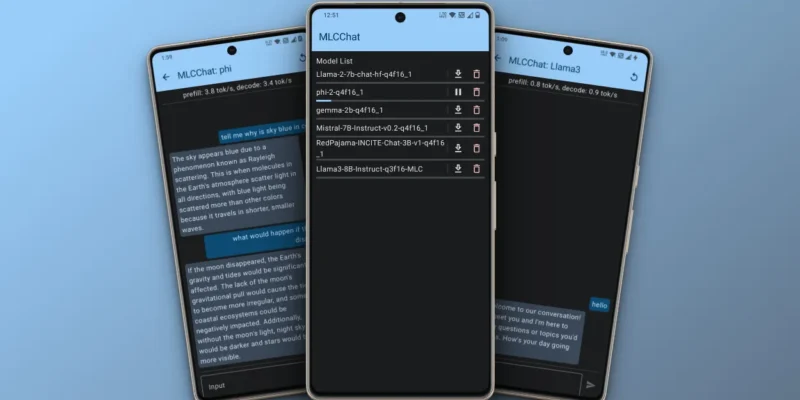
- Next, launch the MLC Chat app and you will see a list of AI models. It supports even the latest Llama 3 8B model, and you have options like Phi-2, Gemma 2B, and Mistral 7B as well.
- I downloaded Microsoft’s Phi-2 model as it’s small and lightweight.
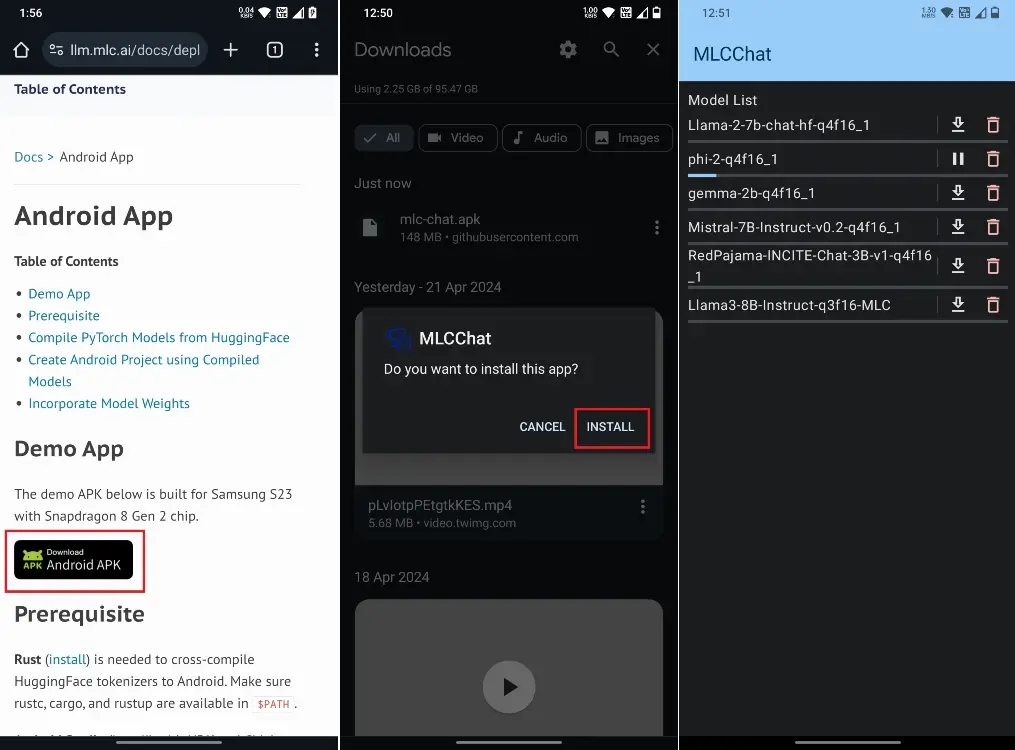
- Once the model is downloaded, tap on the chat button next to the model.
- Now, you can start chatting with the AI model locally on your Android phone. You don’t even need an internet connection.
- In my testing, Phi-2 ran fine on my phone but there was some hallucination. Gemma refused to run. And Llama 3 8B was too slow.
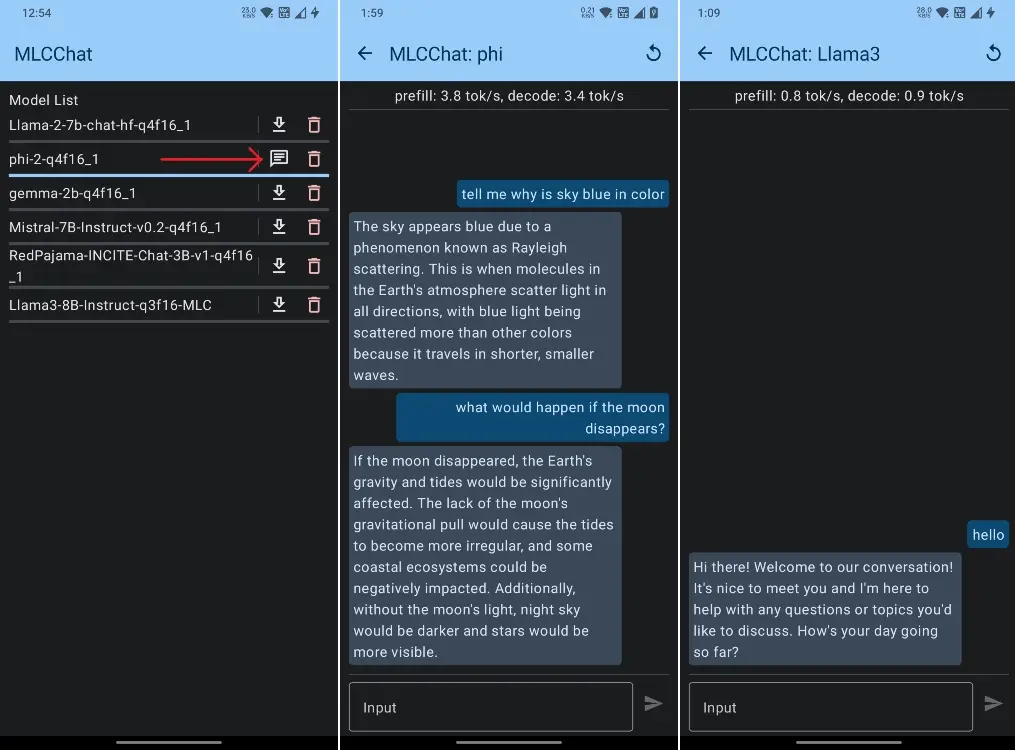
- On my OnePlus 7T which is powered by the Snapdragon 855+ SoC, a five-year-old chip, it generated output at 3 tokens per second while running Phi-2.
So this is how you can download and run LLM models locally on your Android device. Sure, the token generation is slow, but it goes on to show that now you can run AI models locally on your Android phone. Currently, it’s only using the CPU, but with Qualcomm AI Stack implementation, Snapdragon-based Android devices can leverage the dedicated NPU, GPU, and CPU to offer much better performance.
On the Apple side, developers are already using the MLX framework for quick local inferencing on iPhones. It’s generating close to 8 tokens per second. So expect, Android devices to also gain support for the on-device NPU and deliver great performance. By the way, Qualcomm itself says that Snapdragon 8 Gen 2 can generate 8.48 tokens per second while running a larger 7B model. It would perform even better on a 2B quantized model.
Anyway, that is all from us. If you want to chat with your documents using a local AI model, check out our dedicated article. And if you are facing any issues, let us know in the comment section below.