LocalRAG: Deploy a production-grade RAG chatbot on your Local Machine or Server
This Guide will help you to deploy a Production level RAG application into your workstation/local machine or Server. LocalRAG is a is a cool self-hosting application made by Hemachandran Dhinakaran which enables you to inquire about your documents and receive answers while ensuring the privacy and security of your data.
LocalRAG
The LocalRAG application takes the documents (PDF, DOCX, TXT, or MD) as input to establish the chat interface with users solely based on the content of the document along with the chat history. The backend of the application is built using LangChain and Stremlit is used to power the front end.
Prerequisite
Set Up a Python Virtual Environment (optional, but recommended)
Python:
pipenv shell
pipenv install <packages>
pipenv install -r requirements.txtMake sure you have Docker installed on your machine. If not, you can download it from the Docker website. We are going to use
- Qdrant as Vector Store
- Redis Database for Storing the chat messages.
Run the below docker commands in your terminal to start the Qdrant and Redis Container.
docker container run --detach --publish 6379:6379 redis/redis-stack:latest
docker container run --detach --publish 6333:6333 -v /tmp/local_qdrant:/qdrant/storage qdrant/qdrant:latestUpon running the above docker command you should notice something similar like this,

After running both the commands you can check if the container is up and running using the command:
docker ps -a
Setup Ollama:
Ollama is an Open-source Library for running the Large Language Models (LLM) in your local machine/workstation.
1. Download ollama from here and install in your machine.
2. Fire up the terminal and run the command ollama pull <model name> to download the LLM into your workstation. In my case I prefer “llama3” as it is the most capable openly available LLM.
3. Check out the models tab in ollama portal where you can pull the small sized LLM like phi3 and experiment with them. If you are opting for a different model other than llama3 make sure you pass the model name as “model” arguments in app.py
Next up, clone the repository into your local make sure git is installed into your system,
Clone the LocalRAG:
Open the terminal in the folder where you want the scripts to be downloaded and run the below git command,
git clone https://github.com/HemachandranD/awesome_llm_apps.gitPlease note that this will clone my entire repository, where all my resources related to LLM are committed. You can alternatively download the scoped LocalRAG folder for this guide from the link below.
For Linux users, you can check the on_start.sh file in the repo that will perform all the above actions mentioned above considering you have the libraries installed already.
#!/bin/bash# Run this on linux machine to run the ollama
mkdir bin
sudo curl -L https://ollama.com/download/ollama-linux-amd64 -o /bin/ollama
sudo chmod +x /bin/ollama
./bin/ollama pull llama3
mkdir -p ~/log
~/bin/ollama serve > ~/log/ollama.log 2> ~/log/ollama.err &
# Run this to start redis & qdrant locally
docker container run --detach --publish 6379:6379 redis/redis-stack:latest
docker container run --detach --publish 6333:6333 -v /tmp/local_qdrant:/qdrant/storage qdrant/qdrant:latestNow that we have completed all the prerequisite, let’s discuss on how we can run it from your local using Streamlit and Ollama.
Run LocalRAG:
Navigate to the cloned/downloaded LocalRAG Folder and run the Streamlit command:
streamlit run app.py
Your app will be up and running at http://localhost:8501
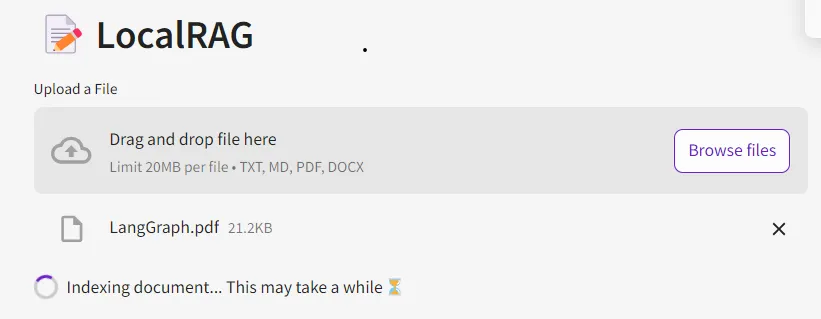
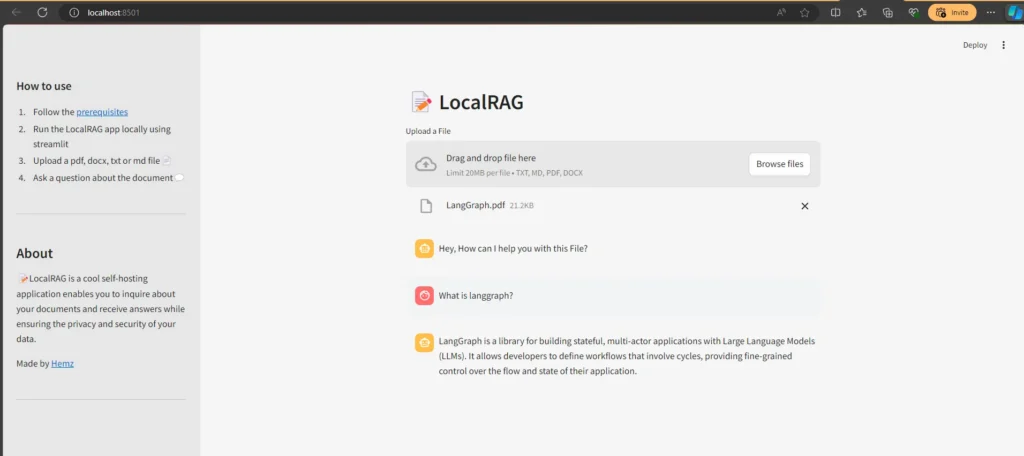
Upload a file:
Uploaded a sample document containing introduction about langgraph.
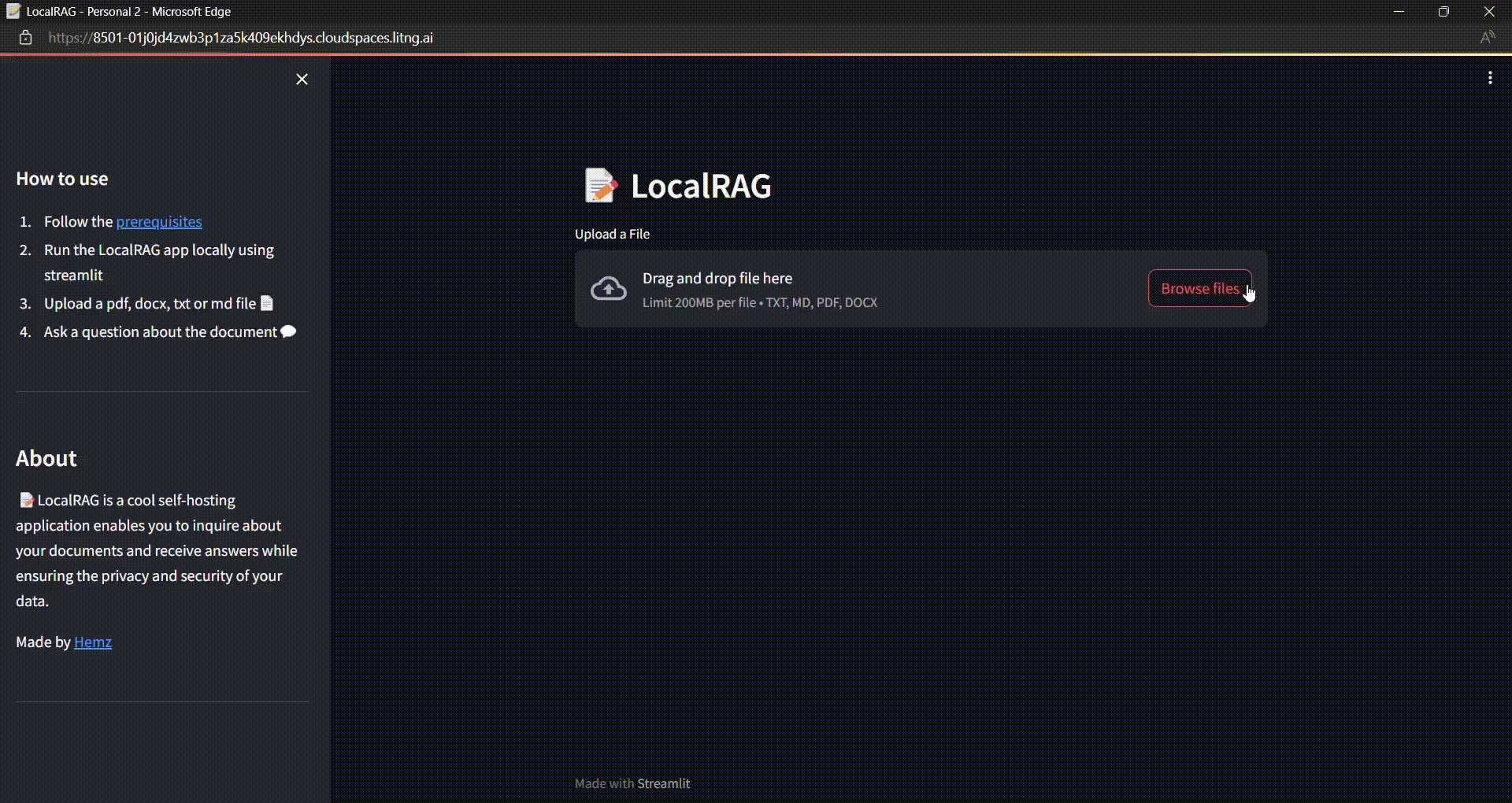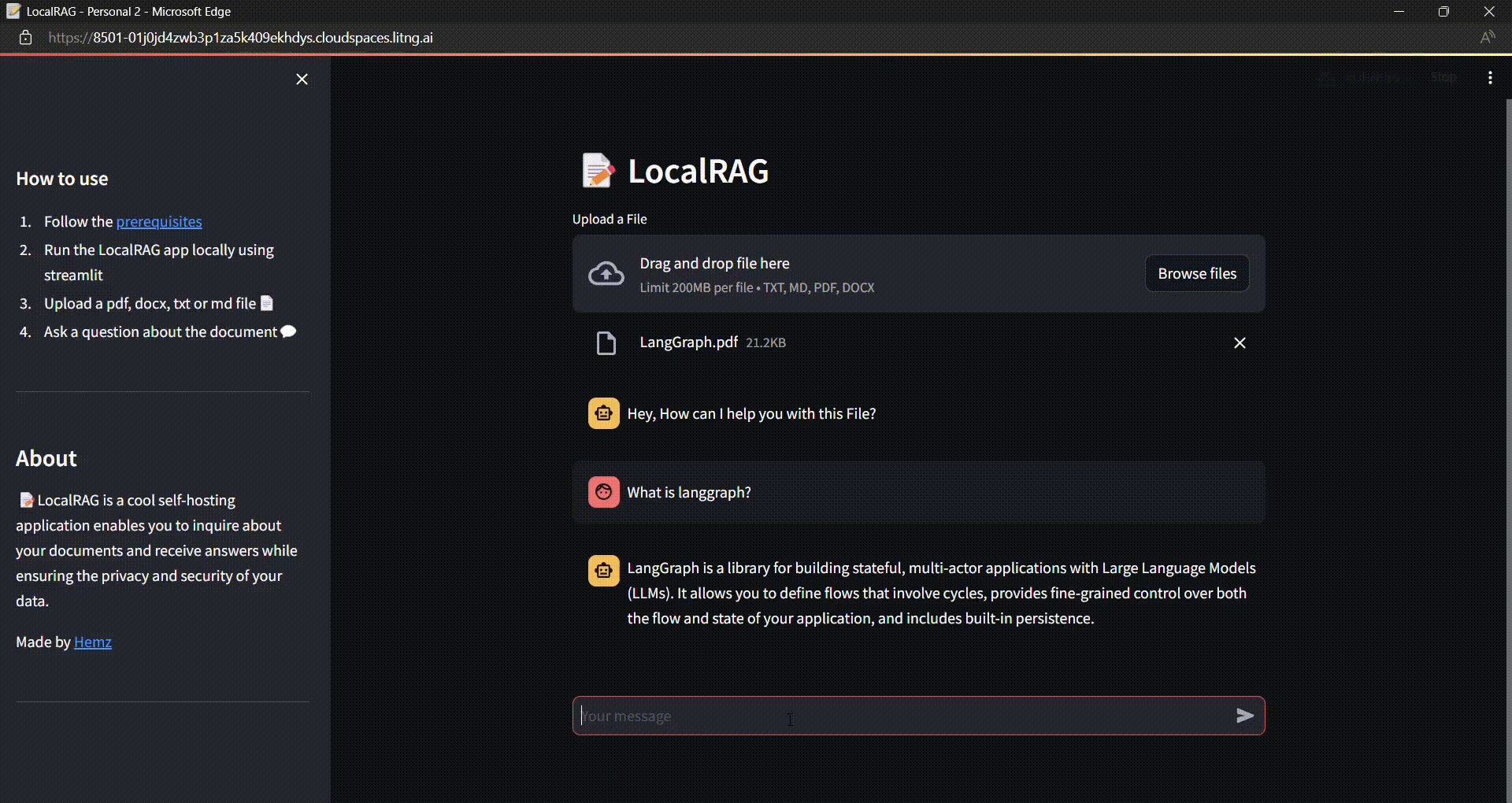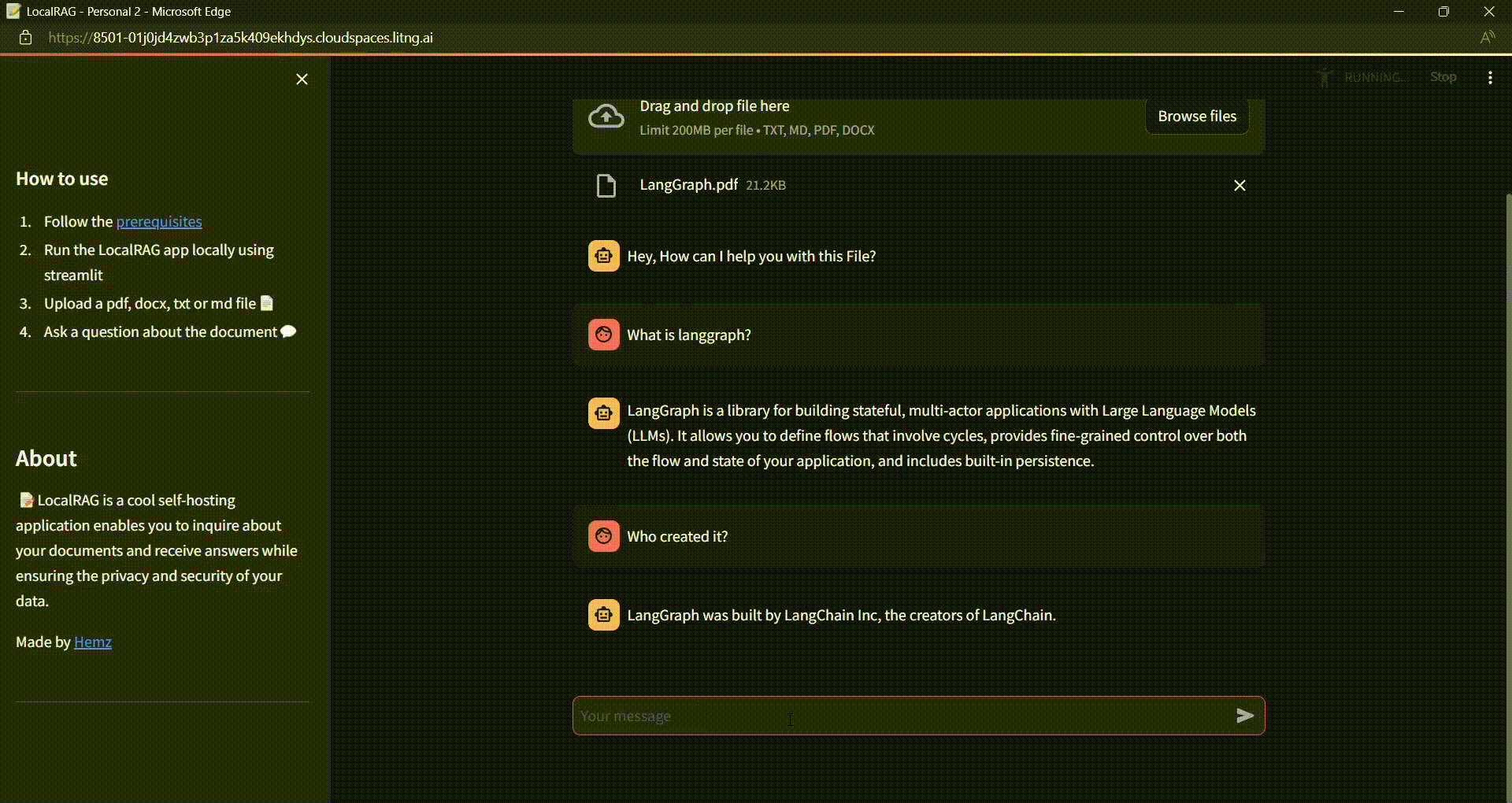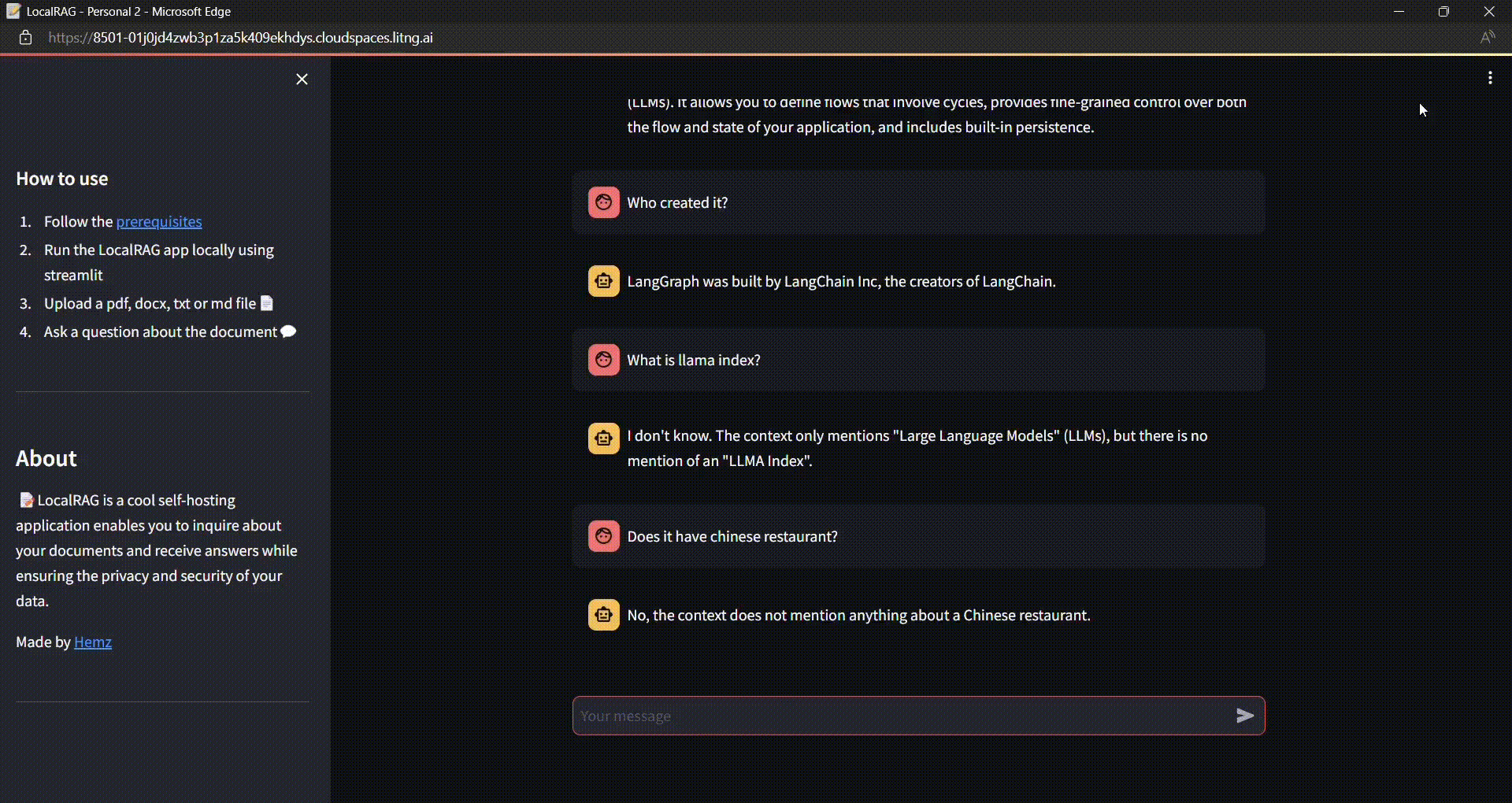
Chat with the Document:
Once you upload the document, the Indexing starts, and the vectors are stored into the Vector store.
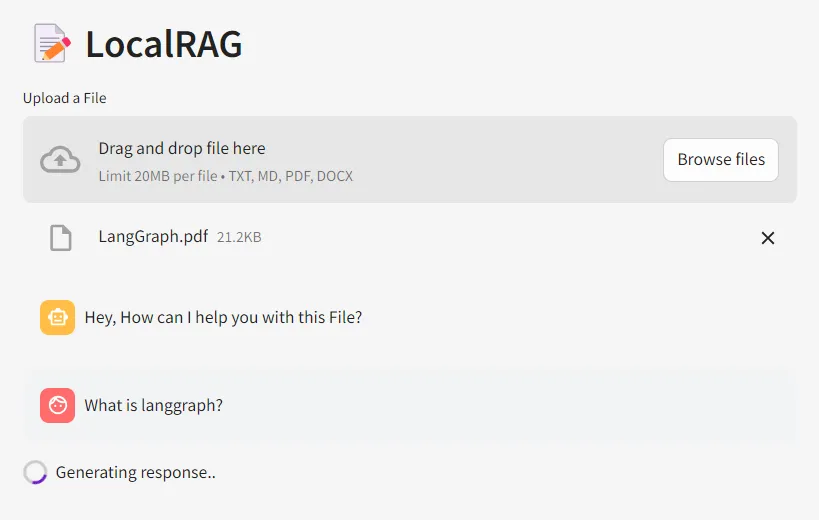
The vectors are retrieved by the retriever based on the similarity search and the LLM responds to the question based on the context provided in the document.
Just being curious on how it responds to unrelated question from the context

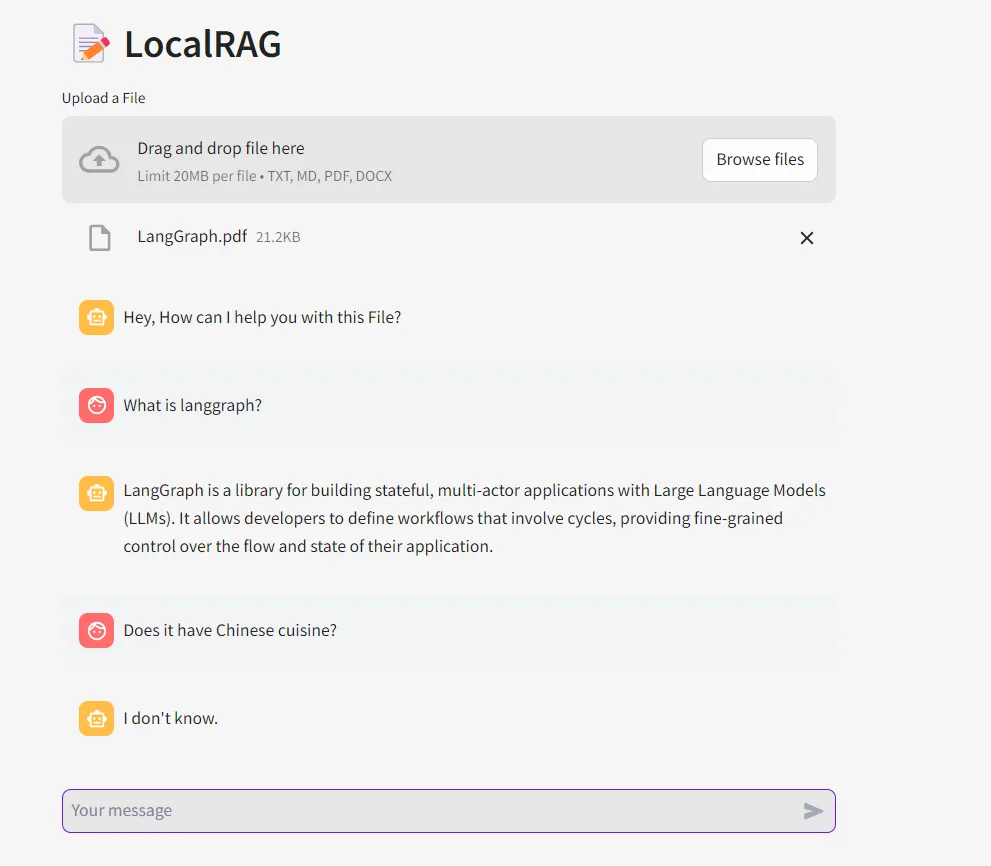
NOTE:
One thing to be noticed is the LLM understood the context of 'it' here by referring the chat history.
Still unclear, take a look at the gif at the top where my first prompt was “What is langgraph?” followed up by “who created it?“. The LLM understood that “it” refers to langgraph here by referring the chat history.
Feel free to reach out to me if you are facing issues while setting up the LocalRAG in your machine. Thanks to Ollama for making our life easier to host the LLM’s on any machine.
Don’t forget to applaud and comment